Our first prototype was a single LLM agent with access to a Gmail tool, a price-fetch tool, and a draft-claim tool. It worked beautifully on the demo path (Best Buy purchase, price drop, draft an email, done), and started failing in subtle, expensive ways as soon as we added a second retailer.
The failures had a pattern. The agent would correctly identify a purchase, then over-eagerly file a claim before checking whether the protection window had even opened. Or it would file an email when the retailer required a chat script. Or it would re-file an already-filed claim because state from the previous run hadn't been threaded through cleanly. Single-agent designs that look fine on the happy path crumble on edge cases because every responsibility is tangled with every other responsibility in a single prompt.
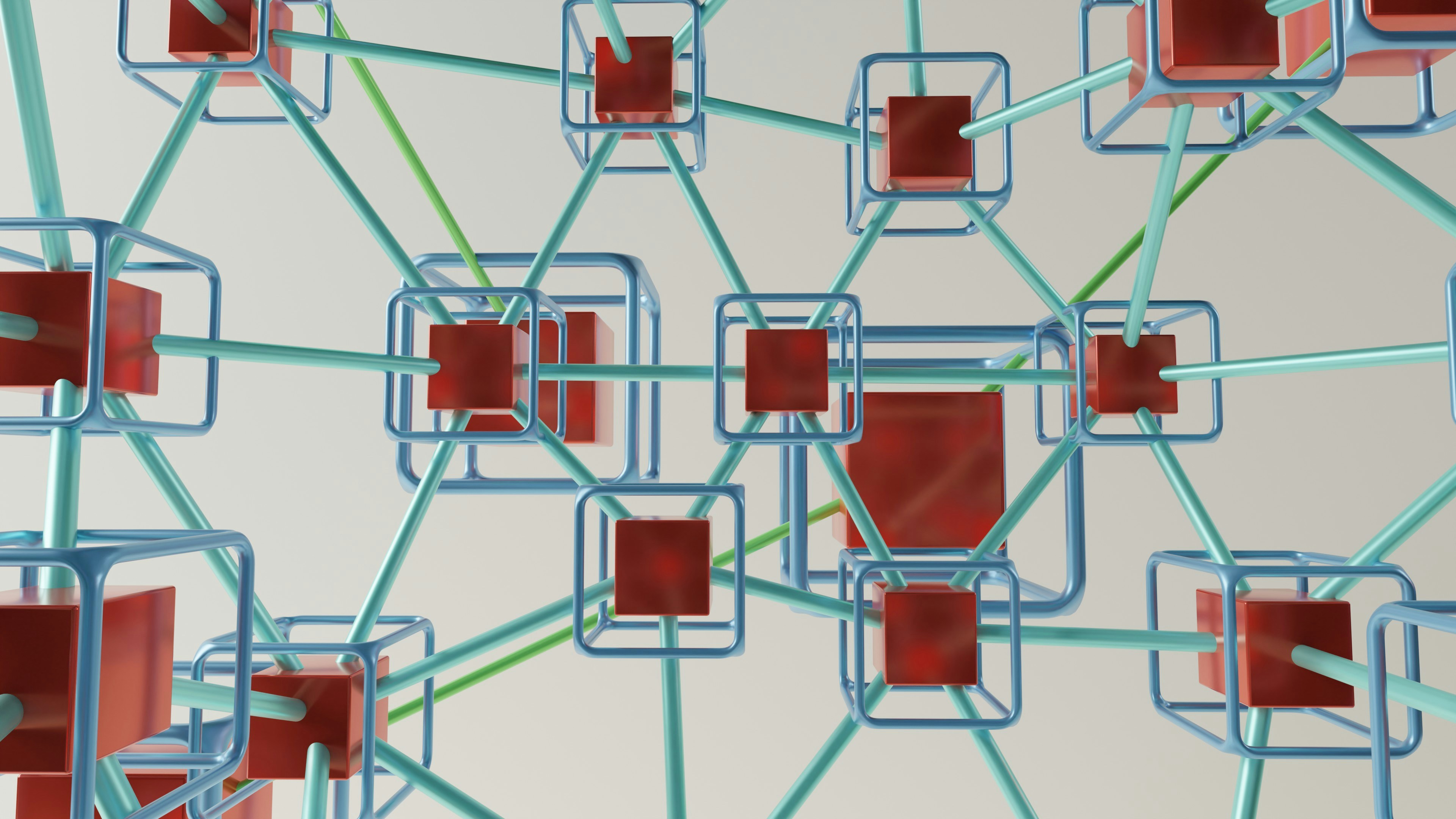
The four agents
We split the work into four specialized sub-agents, each with its own prompt, its own tools, and its own success criteria.
1. Purchase agent
Reads Gmail purchase confirmations and extracts structured purchase data: retailer, product, price, date, order ID, return-window estimate. It does one thing (turn email into structured records) and never decides whether a claim should be filed.
2. Price agent
Given a structured purchase, monitors the price across the relevant platform. It owns the question "has the price dropped enough to be worth filing?" and nothing else. Crucially, it doesn't know how to file. Only how to detect.
3. Claim agent
Given a confirmed eligible drop, drafts the appropriate claim artifact: email body, chat script, in-store talking points, or a self-service portal walkthrough. Retailer-specific knowledge lives here. The claim agent never sends. It drafts.
4. Outcome agent
Handles approved/denied/no-response outcomes after a claim has been filed. Routes denials to retry strategies (different framing, different channel) and aggregates outcomes back into the user's dashboard.
Why the separation matters
Each agent has a smaller, sharper prompt. Each agent has clearer success criteria, which means we can evaluate them independently: purchase extraction accuracy, drop detection precision/recall, claim approval rate, outcome routing correctness. When the system fails, we can almost always isolate which agent failed, instead of staring at a 200-line monolithic prompt and guessing.
We run all four on Google Cloud's Agent Engine. Inter-agent state is passed as structured JSON through a shared state graph, not through chained natural-language outputs. That was another lesson: LLM agents are terrible at reliably consuming free-form text from other LLM agents. Make them consume structured records.
If you're building a multi-step agent system: separate detection from execution. Single-agent designs that conflate the two will look great in demos and break the moment you add a second platform.
What we got wrong
We initially had five agents. The fifth was a "planner" that decided which other agents to invoke. It added zero accuracy, doubled latency, and made debugging twice as hard. We deleted it. Routing logic ended up being deterministic state-machine code, not an LLM call, which is unfashionable to say but correct.
If you're working on something similar, talk to us. We don't think anyone has the right answer here yet, but we'd love to compare notes.
The ClaimIt engineering team
Engineering